1 - 动态路由
自定义路由
路由规则分类
规则路由是一种根据一段DSL(路由规则)来控制消息分流的机制。
路由规则分为被调规则和主调规则2部分:
-
被调规则代表的是当服务作为被调方时,控制所有主调方进行流量转发的规则。
-
主调规则代表的是当服务作为主调方时,控制所有被调方进行流量转发的规则。

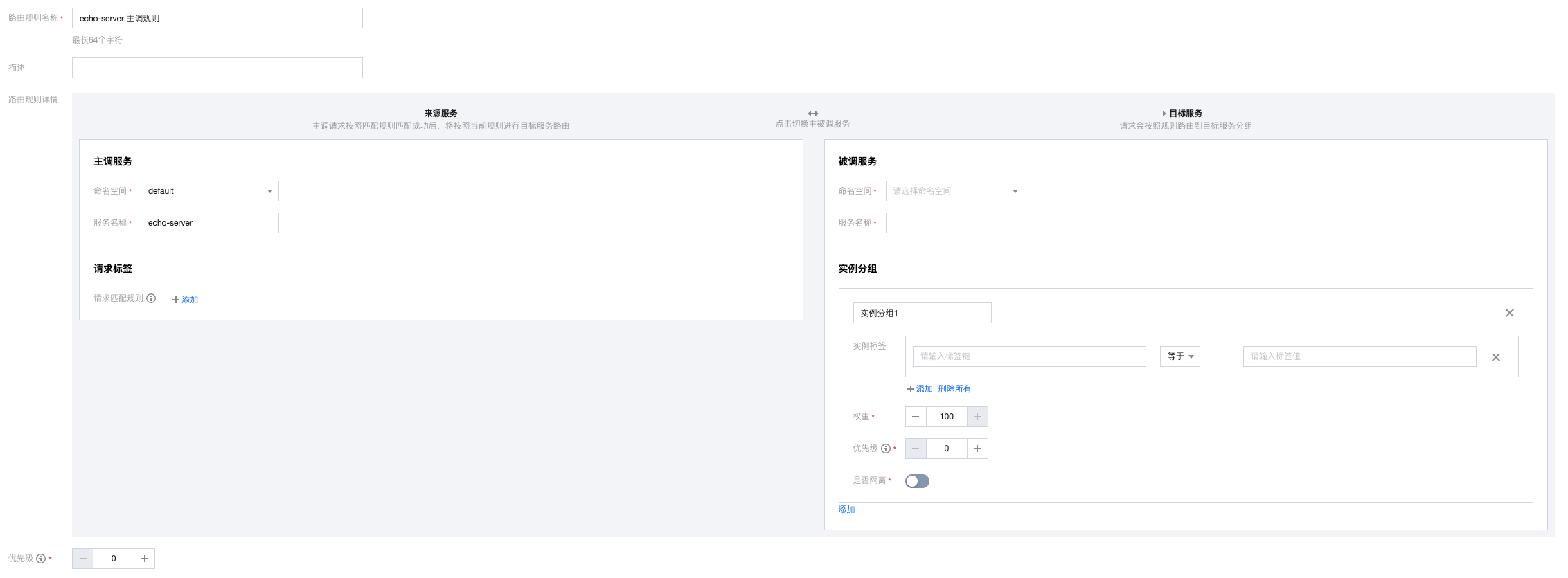
服务上可以配置主调规则和被调规则,如下图所示:
- 主调规则
- 被调规则
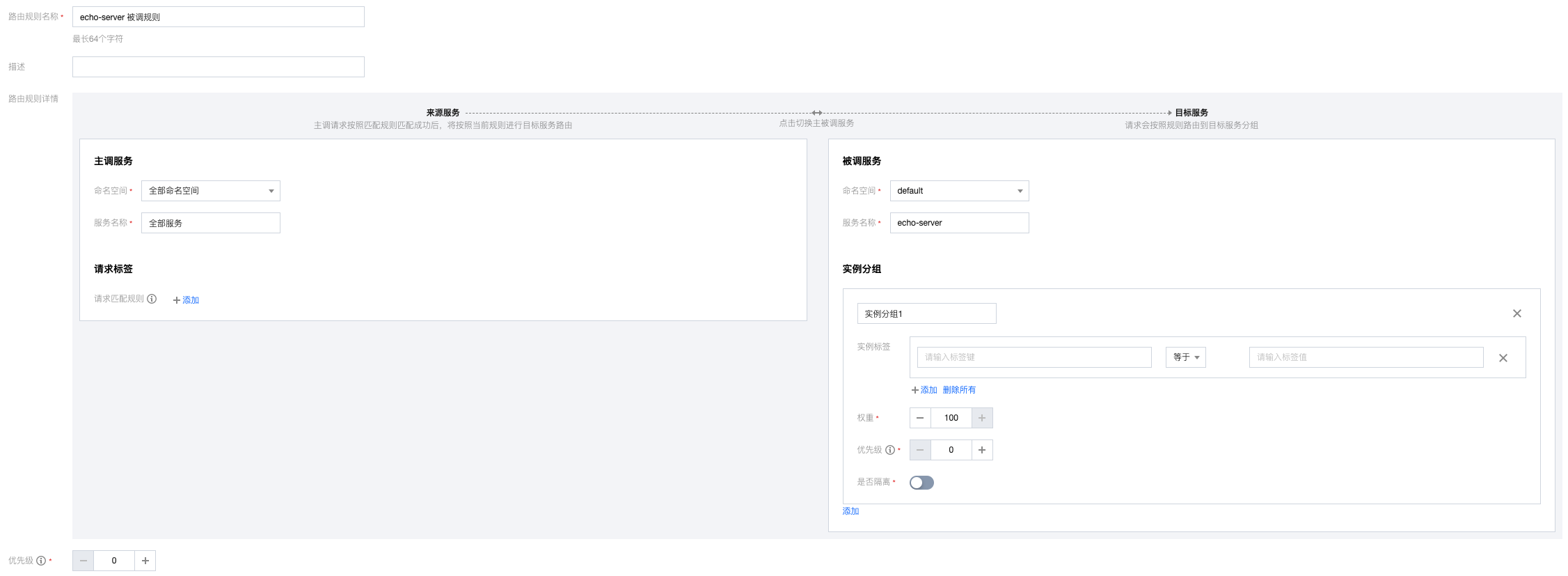
配置被调规则
被调规则在服务作为被调方时候生效,配置界面如下:

图上的规则的含义是:当echo-server(服务名)作为被调方时,对于所有主调方过来的,带有user-type:1的标签的请求,都路由给自身服务版本号为1.0.0的实例分组。
配置主调规则
主调规则在服务作为主调方时候生效,配置界面如下:
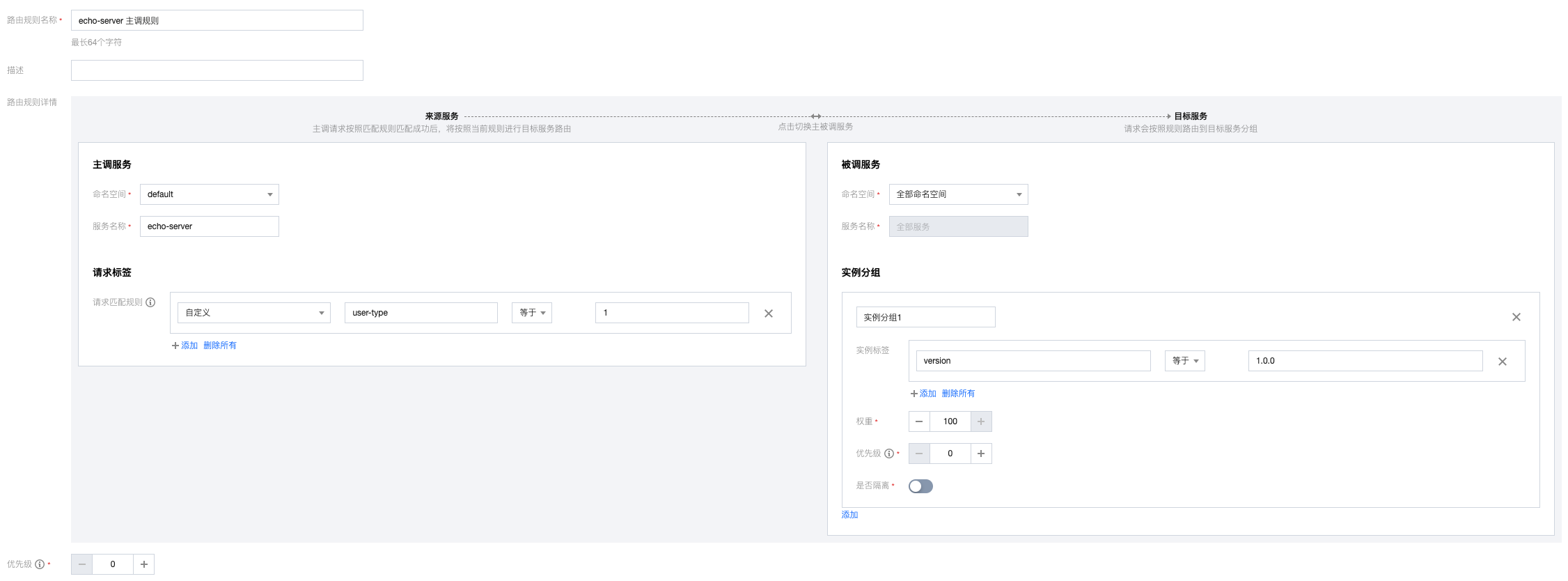
图上的规则的含义是:当echo-server(服务名)作为主调方时,对于发出去的请求,带有user-type:1的标签的请求,都路由给目标服务版本号为1.0.0的实例分组。
路由规则的匹配流程
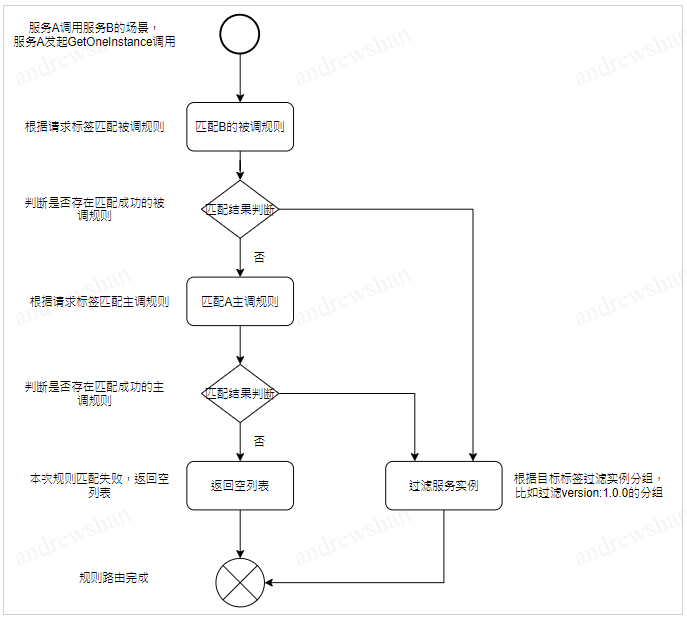
请求匹配规则
可选,指定限流规则的请求参数匹配条件,不填代表不过滤,支持以下四种参数类型:
-
自定义参数:自定义KEY和VALUE,具体的请求参数值可通过SDK进行传入。
-
请求头(HEADER):针对协议消息头(http header/grpc header)进行过滤。
-
请求参数(QUERY):针对协议请求参数(http query)进行过滤。
-
请求COOKIE(COOKIE):针对协议 cookie 参数(http cookie)进行过滤。
-
方法(METHOD):针对协议的METHOD(http method/grpc method)进行过滤。
-
主调IP(CALLER_IP):针对主调方机器的IP地址进行过滤。
-
路径(PATH):针对协议请求路径进行过滤
每种类型参数值支持以下几种值匹配模式:
-
全匹配:全值匹配,传入的值与配置的值相同才匹配通过。
-
正则表达式:用户配置正则表达式,通过正则表达式对传入的值进行匹配,正则表达式支持Google RE2标准。
-
不等于:取反匹配,传入的值与所配置的值不相等才算匹配成功。
-
包含:多字符串取OR匹配,传入的值只要匹配到其中一个字符串,就算匹配成功。字符串之间使用逗号进行分割。值格式为’value1,value2,value3‘,匹配到其中一个就算成功。
-
不包含:多字符串取反匹配,传入的值必须都没有出现在所配置的字符串列表中,才算匹配通过。值格式为’value1,value2,value3‘,全部不等于才算成功。
边界条件
- 通过请求标签进行匹配,没有匹配到一个路由规则,则本次请求路由失败,返回空实例列表。
- 通过请求标签进行匹配,匹配到了路由规则,但是路由规则所对应的destination不存在服务实例,则本次请求获取到的服务实例为空。
- 通过请求标签进行匹配,匹配到了路由规则,路由规则对应的2个同优先级的destination,请求会在这2个destination中按照权重比例随机路由,假如其中一个destination不存在服务实例,则路由到该destination的请求获取到的服务实例为空。
自定义路由实践
按版本号灰度实践
场景描述
请求通过网关接入,路由到后端服务。后端服务上线了新版本,新版本只对打了标签的用户请求开放,未打标签的请求继续路由到老版本。
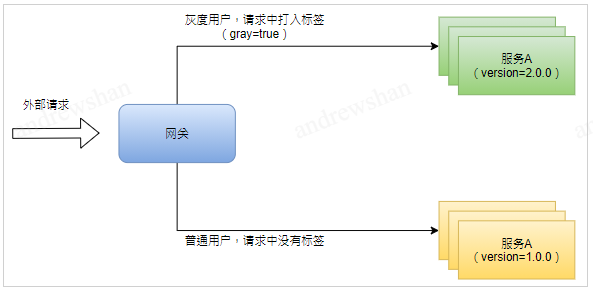
使用方式
-
配置路由规则
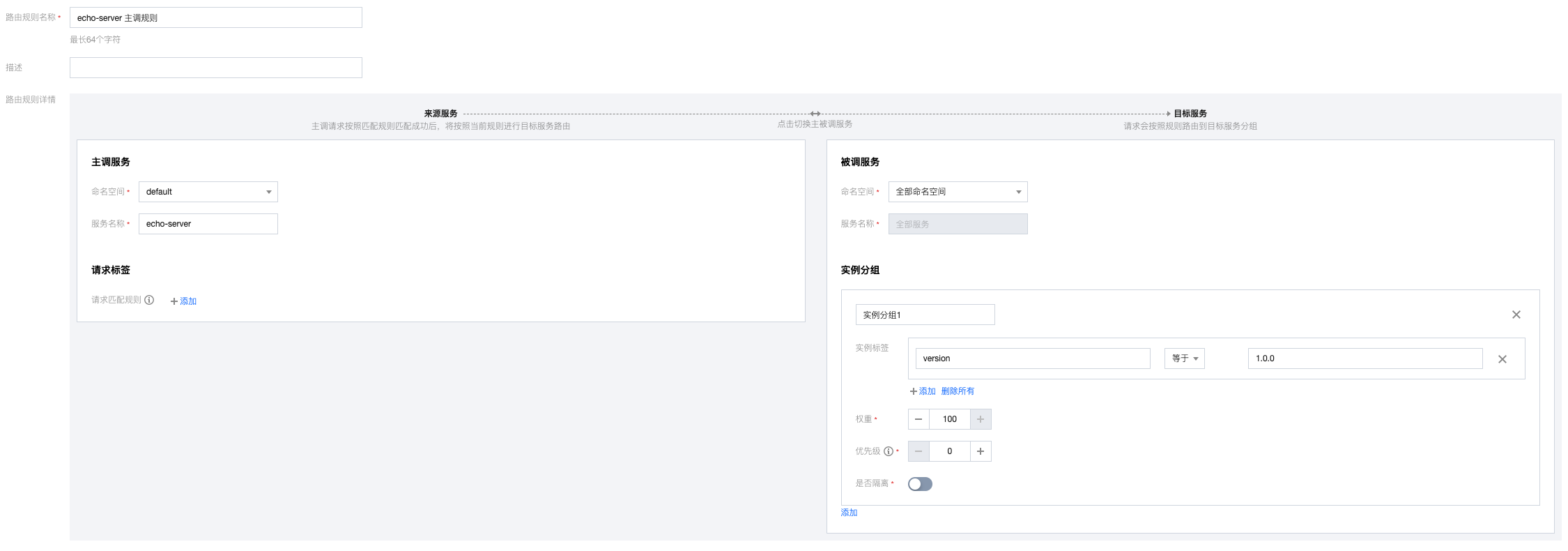
由于新版本上线的行为发生在被调方,主调方并不感知被调是否上线了新版本服务,因此路由规则需要配置在被调方。配置一个被调规则,指定只有gray=true的请求,才流入版本号为2.0.0的实例分组,其他请求则流入版本号为1.0.0的实例分组。
(1) 配置兜底规则:将请求导入到1.0.0版本的分组。
(2) 配置灰度规则:将gray=true的请求导入到2.0.0版本的分组,不存在2.0.0分组时,请求导入到1.0.0的分组。
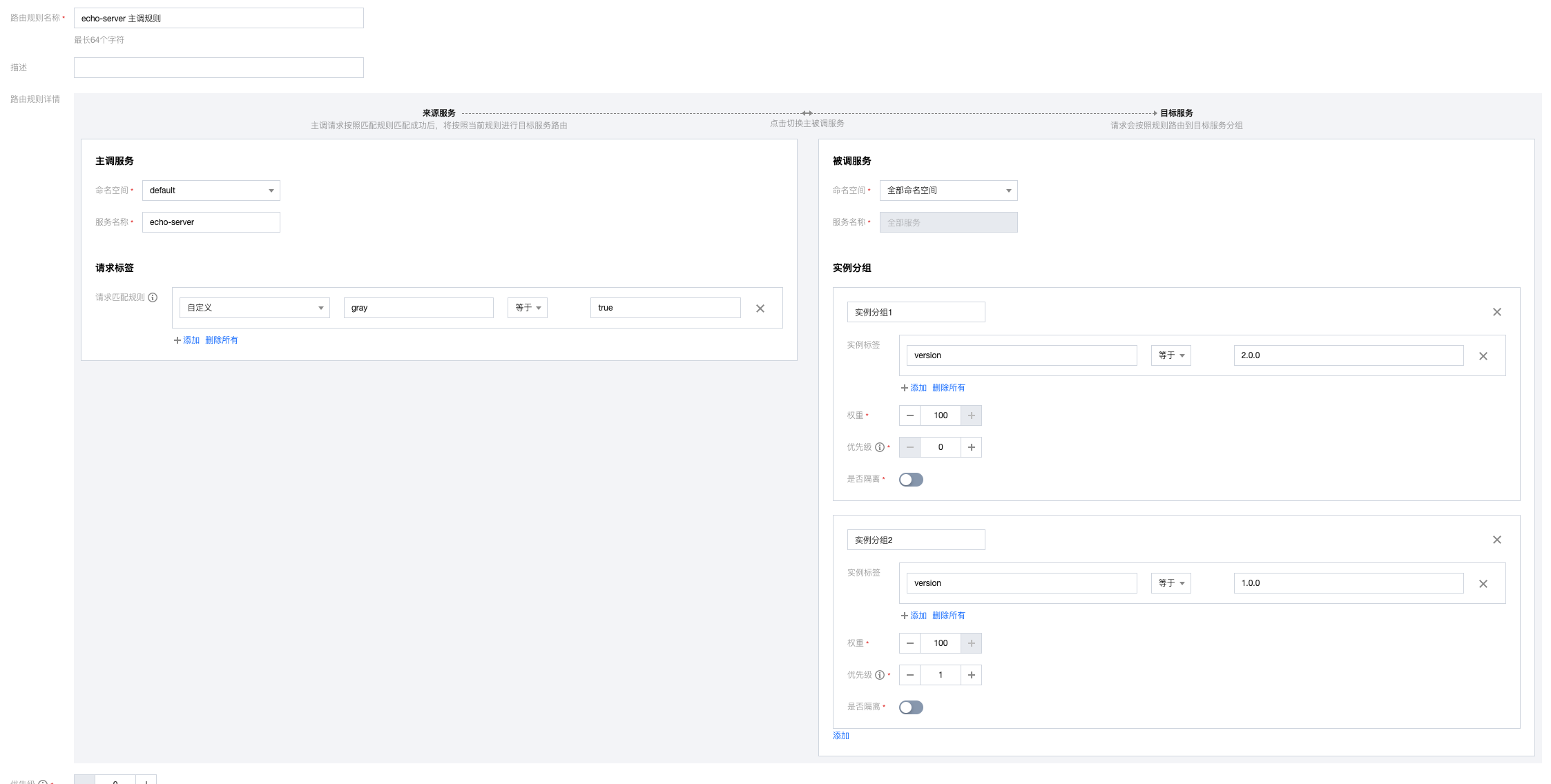
(3) 规则列表:将按顺序进行匹配执行规则。

-
执行服务路由
可以执行各个语言SDK的版本号路由样例进行服务路由功能的执行,执行完可以通过调用结果可以看到灰度的请求都流向了版本号2.0.0的分组。
多环境隔离实践
场景描述
使用微服务架构时,一个业务数据流通常需要跨多个微服务才能完成。而在业务开发过程中,通常会有以下诉求:
- 为了提升开发效率,不同特性开发人员,需要使用特性环境进行并发开发测试联调,特性环境之间需要进行隔离;
- 同时为了降低部署成本,开发测试时,只需要部署特性变更所涉及的服务,链路其他未更改的服务,统一使用基线环境的服务。
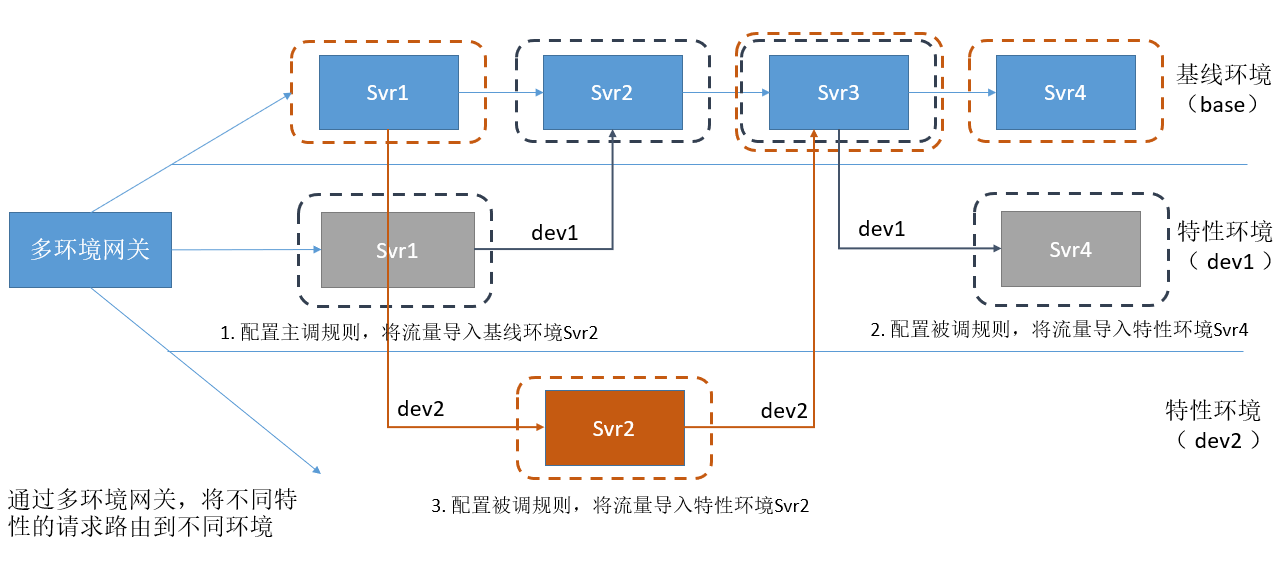
使用方式
- 配置路由规则
本次场景,存在2个特性并行开发,特性(dev1)涉及修改的微服务为Svr1和Srv4,特性(dev2)涉及修改的微服务为Svr2。其他不涉及修改的微服务,在开发联调过程中,统一使用基线环境的服务。 为了防止混乱,每个特性开发人员只允许针对自己涉及修改的微服务添加针对当前特性的规则,不涉及修改的微服务不允许添加规则。
(1)所有的服务默认配置一个兜底规则,将请求导入到基线环境。
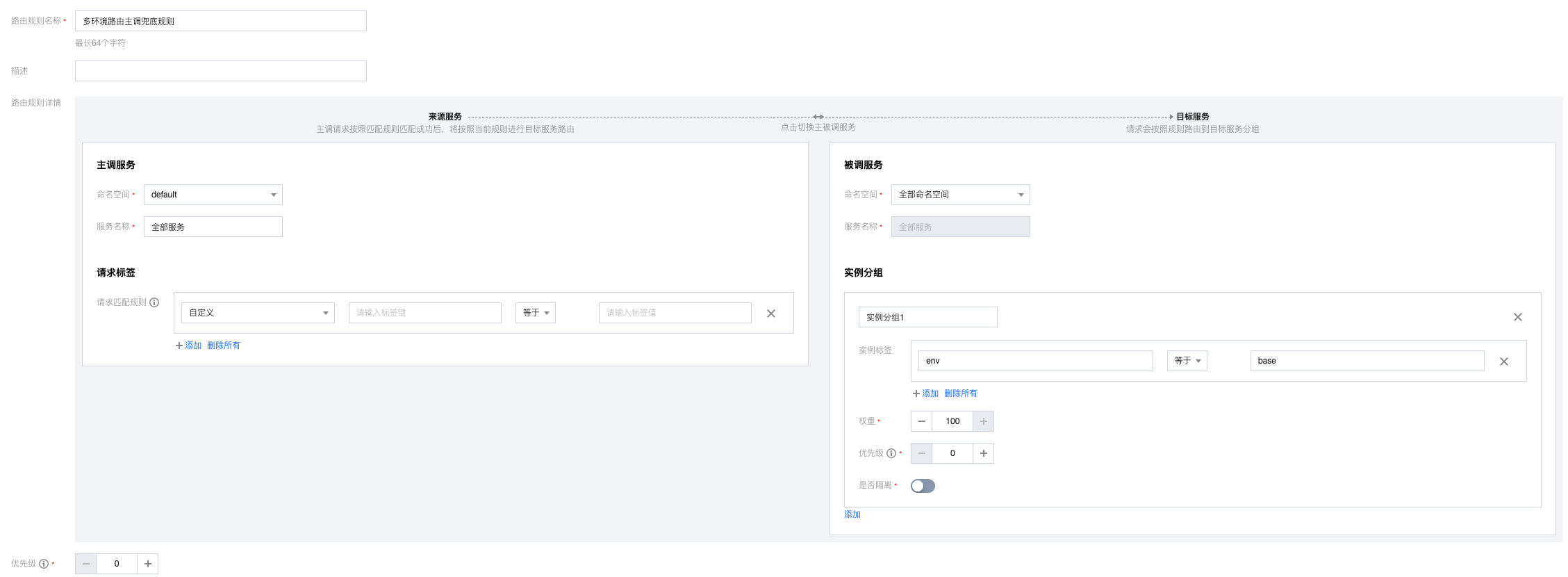
(2)Srv1服务添加一个主调规则,将来源dev1请求路由到dev1的Svr2。
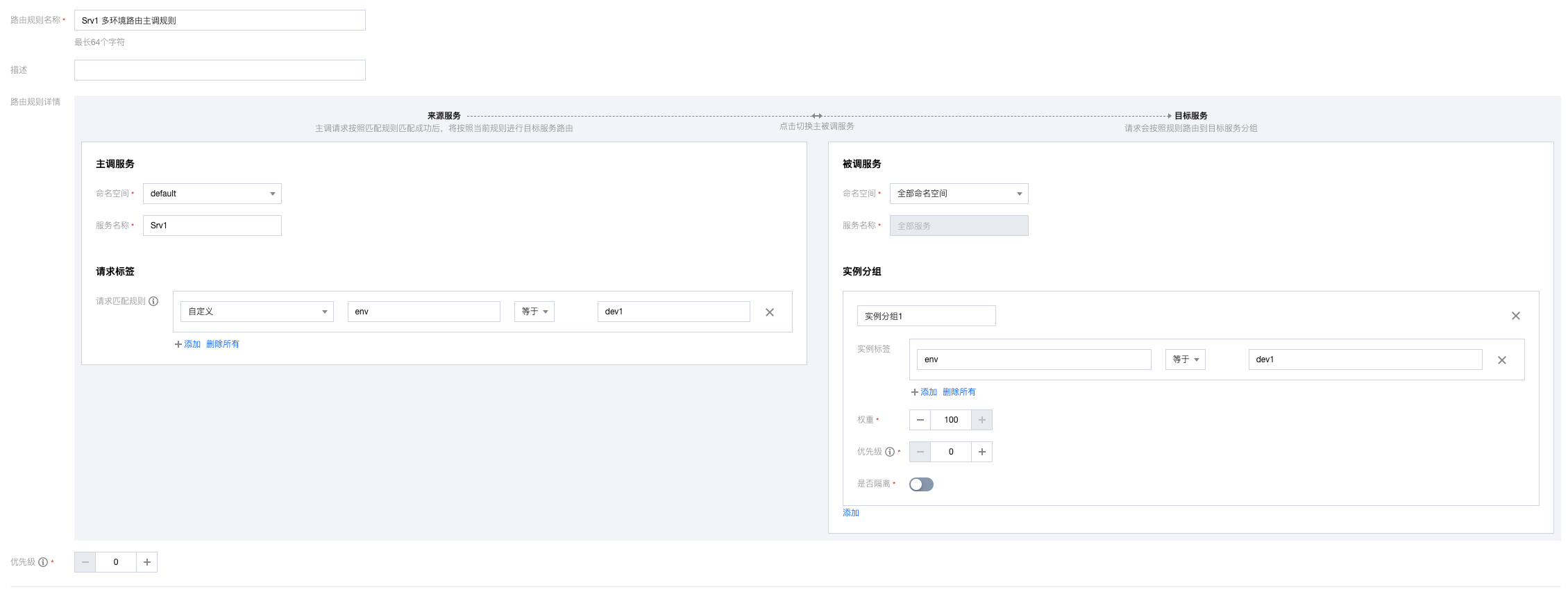
(3)Svr4服务添加一个被调规则,将来源dev1请求路由到dev1的Svr4。

(4)Svr2服务添加一个被调规则,将来源dev2请求路由到dev2的Svr2。

-
执行服务路由
可以执行各个语言SDK的多环境路由样例进行服务路由功能的执行,执行完可以通过调用结果可以看到不同特性环境的请求都流向了对应特性环境的分组。
2 - 就近路由
功能描述
北极星提供基于 地域(region) - 城市(zone) - 园区(campus) 这3元组组成的地域信息进行就近路由的能力,能够根据主调的地域信息,结合被调实例的地域信息,进行匹配。实例本身的地域信息来源于有以下几个途径
服务端的 CMDB 插件
- 参考 cmdb 插件开发
客户端的 Location 插件
- 提供 Location 插件,用户可以根据 polaris客户端 中对于 Location 插件的定义,根据客户端所在环境的特性来实现不同的本地地址位置信息获取插件
- env: 将地理位置信息注入至客户端所在机器的环境中,客户端就可以基于系统环境变量自动获取地理位置信息
配置设计
polaris-go 客户端使用
SDK配置属于客户端全局配置,基于该SDK实例所发起的服务发现,都遵循该就近路由策略。 由于就近路由能力通过SDK服务路由模块的插件进行提供,因此就近路由相关配置,也作为插件的特有配置来进行提供。
global:
# 地址提供插件,用于获取当前SDK所在的地域信息
location:
providers:
- type: local
region: ${REGION} # 从环境变量 REGION 中读取
zone: ${ZONE} # 从环境变量 ZONE 中读取
campus: ${CAMPUS} # 从环境变量 CAMPUS 中读取
consumer:
serviceRouter:
# 服务路由链
chain:
- nearbyBasedRouter
# 插件特定配置
plugin:
nearbyBasedRouter:
# 默认就近区域:默认城市
matchLevel: zone
# 最大就近区域,默认为空(全匹配)
maxMatchLevel: zone
polaris-java 客户端使用
SDK配置属于客户端全局配置,基于该SDK实例所发起的服务发现,都遵循该就近路由策略。 由于就近路由能力通过SDK服务路由模块的插件进行提供,因此就近路由相关配置,也作为插件的特有配置来进行提供。
global:
location:
providers:
- type: local
options:
region: ${REGION:} # 从环境变量 REGION 中读取
zone: ${ZONE:} # 从环境变量 ZONE 中读取
campus: ${CAMPUS:} # 从环境变量 CAMPUS 中读取
serviceRouter:
chain:
# 就近路由
- nearbyBasedRouter
plugin:
nearbyBasedRouter:
#描述: 就近路由的最小匹配级别。region(大区)、zone(区域)、campus(园区)
matchLevel: zone
#描述: 最大匹配级别
maxMatchLevel: all
服务配置
- 在控制台上通过可视化的方式操作开关就近路由。
-

就近流程
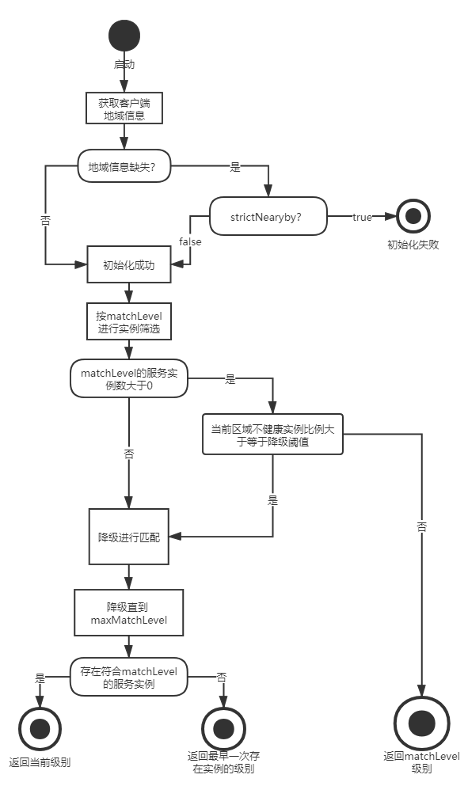
初始化
- 用户调用NewConsumerAPI或者NewProviderAPI后
- SDK 会使用客户端节点的 IP,往 Polaris 服务端查询该 IP 对应的 CMDB 信息,查询后的结果后返回给客户端
- 如果查询的结果中,没有携带地址信息,则客户端会走自己本地的 CMDB 插件查询客户端的地理位置信息
地域匹配
服务调用过程中,使用拉取的客户端地域信息,进行全词匹配。匹配规则如下:
- 优先按照 matchLevel 进行匹配,匹配不成功(实例不存在或者可用实例比例少于阈值),则进行降级
- 就近降级按照 degrade 所配置的策略进行降级,会进行逐级的降级匹配,直到 lowestMatchLevel
降级策略
| 降级策略:服务实例不可用 | 降级策略:服务实例不存在 | |
|---|---|---|
| matchLevel区域不存在实例 | 逐级降级直到maxMatchLevel。若实例全部不存在,返回LocationMismatch错误 | 逐级降级直到maxMatchLevel,若都不存在,返回LocationMismatch错误 |
| matchLevel区域存在实例,区域中不可用实例百分比大于等于降级比例 | 返回matchLevel区域实例 | 逐级降级直到maxMatchLevel,若都不满足健康实例返回条件,返回实例数大于0的最小区域实例 |
被调信息异常策略
| maxMatchLevel != "" | maxMatchLevel == “” | |
|---|---|---|
| 被调实例对应的CMDB字段缺失 | 忽略该实例 | 当降级到最高匹配级别(全匹配)时,会返回这部分服务实例 |
跨机房容灾场景
背景
服务端有广州云、深圳、南京云设备。客户端在深圳。 那么深圳客户端访问这个服务端时,返回实例列表由深圳、广州、南京实例组成,同时设置优先级,让深圳客户端优先访问深圳;然后是广州(同可用区);最后是南京
解决方案
假设存在服务A,服务A下面节点存在分别属于深圳、广州、南京的实例,CMDB信息如下:
- 华南/ap-guangzho/ap-guangzhou-3
- 华南/ap-shenzhen/ap-shenzhen-2
- 华东/ap-nanjing/ap-nanjing-4
客户端配置:
consumer:
serviceRouter:
plugin:
nearbyBasedRouter:
# 默认按zone进行就近
matchLevel: zone
就近逻辑
客户端配置 matchLevel: zone,默认只访问同 zone(深圳) 的实例,当深圳可用区无实例后,降级访问 region(华南) 的 实例(可访问广州的实例),当华南地区实例也达到降级条件后,降级访问全部 region(包含华东-南京) 的实例
3 - 访问限流
限流规则说明
北极星支持在界面配置单机限流规则,通过以下路径可以打开限流规则的编辑页面:控制台->服务列表->具体服务->限流规则->新建,打开后,规则各配置项说明如下:
限流类型
- 单机限流:单机限流是一种通过统计单机QPS指标,当达到规则指定阈值时对流量进行限制,保障服务实例不被瞬时流量给冲垮。
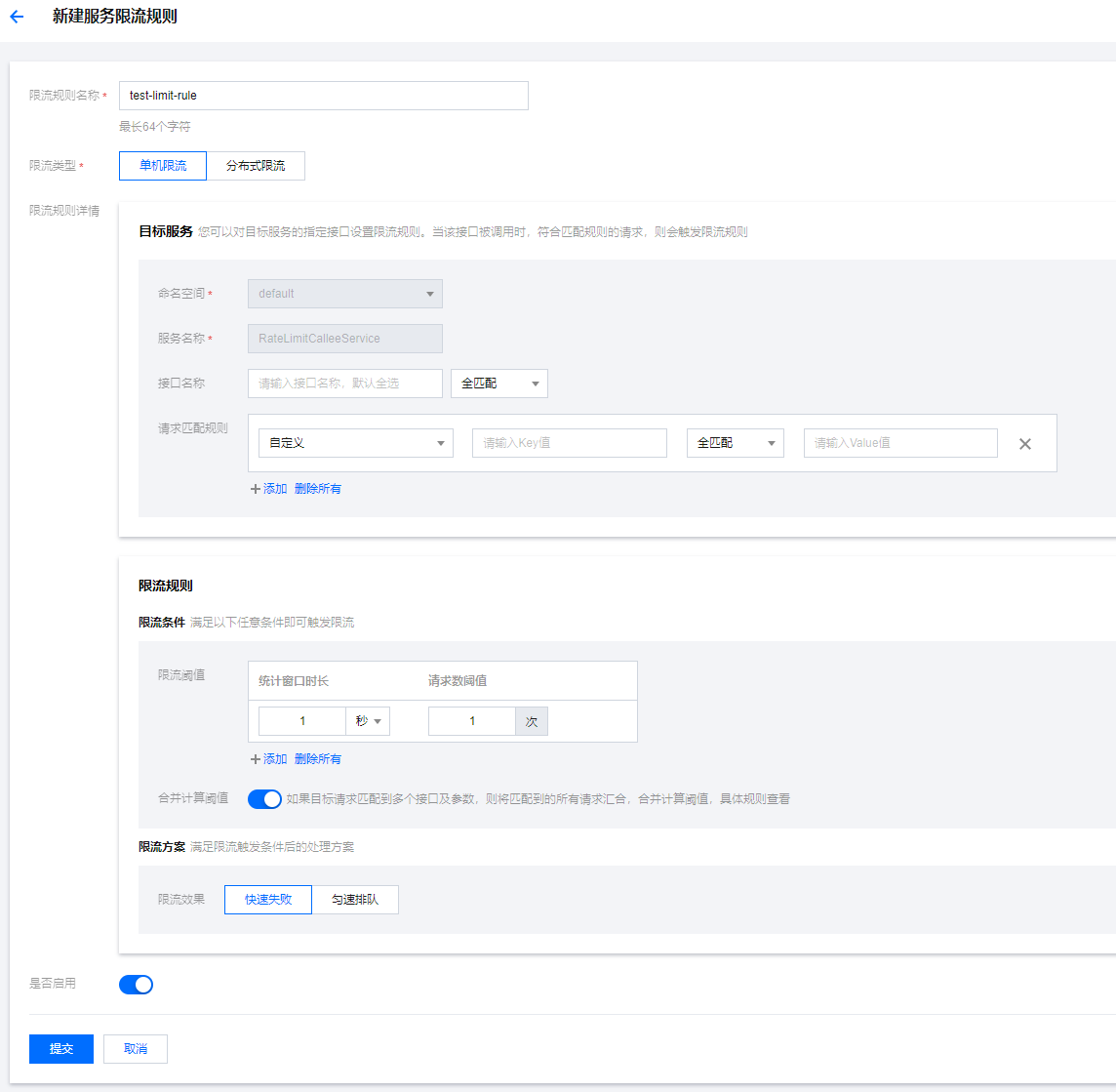
- 分布式限流:分布式限流是一种通过统计全局QPS指标,当达到规则指定阈值时对流量进行限制,保障服务实例不被瞬时流量给冲垮。
接口名称
可选,指定限流规则的接口过滤参数,接口名可对应方法名、http url等信息,不填代表不过滤。
- 接口:规则生效所对应的接口名,用于匹配客户端传入的method参数,默认为
空(全部) - 匹配方式:接口字段的匹配方式,支持全匹配、不等于、包含、不包含、正则表达式四种匹配模式
请求匹配规则
可选,指定限流规则的请求参数匹配条件,不填代表不过滤,支持以下四种参数类型:
-
自定义参数:自定义KEY和VALUE,具体的请求参数值可通过SDK进行传入。
-
请求头(HEADER):针对协议消息头(http header/grpc header)进行过滤。
-
请求参数(QUERY):针对协议请求参数(http query)进行过滤。
-
方法(METHOD):针对协议的METHOD(http method/grpc method)进行过滤。
-
主调服务:针对微服务调用场景下,主调方的服务名进行过滤。
-
主调IP:针对主调方机器的IP地址进行过滤。
每种类型参数值支持以下几种值匹配模式:
-
全匹配:全值匹配,传入的值与配置的值相同才匹配通过。
-
正则表达式:用户配置正则表达式,通过正则表达式对传入的值进行匹配,正则表达式支持Google RE2标准。
-
不等于:取反匹配,传入的值与所配置的值不相等才算匹配成功。
-
包含:多字符串取OR匹配,传入的值只要匹配到其中一个字符串,就算匹配成功。字符串之间使用逗号进行分割。值格式为’value1,value2,value3‘,匹配到其中一个就算成功。
-
不包含:多字符串取反匹配,传入的值必须都没有出现在所配置的字符串列表中,才算匹配通过。值格式为’value1,value2,value3‘,全部不等于才算成功。
限流阈值
指定统计周期内的统计阈值,达到阈值则进行限流。可以配置多个限流阈值,多个限流阈值可同时生效,任意触发了一个就进行限流。
- 统计时长:限流阈值的统计时长,单位秒,默认为1秒
- 请求数:达到限流条件的请求数阈值。默认为1
限流效果
限流阈值被触发后,如何进行对流量进行限制,目前支持2种模式(默认为直接拒绝):
- 直接拒绝:当统计时长内请求数达到阈值,后续新的请求会被拒绝,直到下个统计周期到来才恢复。
- 匀速排队:基于漏桶算法,将请求数平均分配到统计时长内(细分的最小度量单位为1ms),从而控制请求以均匀的速度通过。
失败退化策略
分布式限流需要依赖token server,如果出现token server不可访问,则客户端可以根据配置的规则进行降级,保证用户请求最大限度不受影响。
- 退化成单机限流:默认策略。直接退化成单机计算配额的方式进行限流,单机配额=(全局配额/节点数)。
- 直接通过:不执行限流,所有请求都直接放通。
使用场景
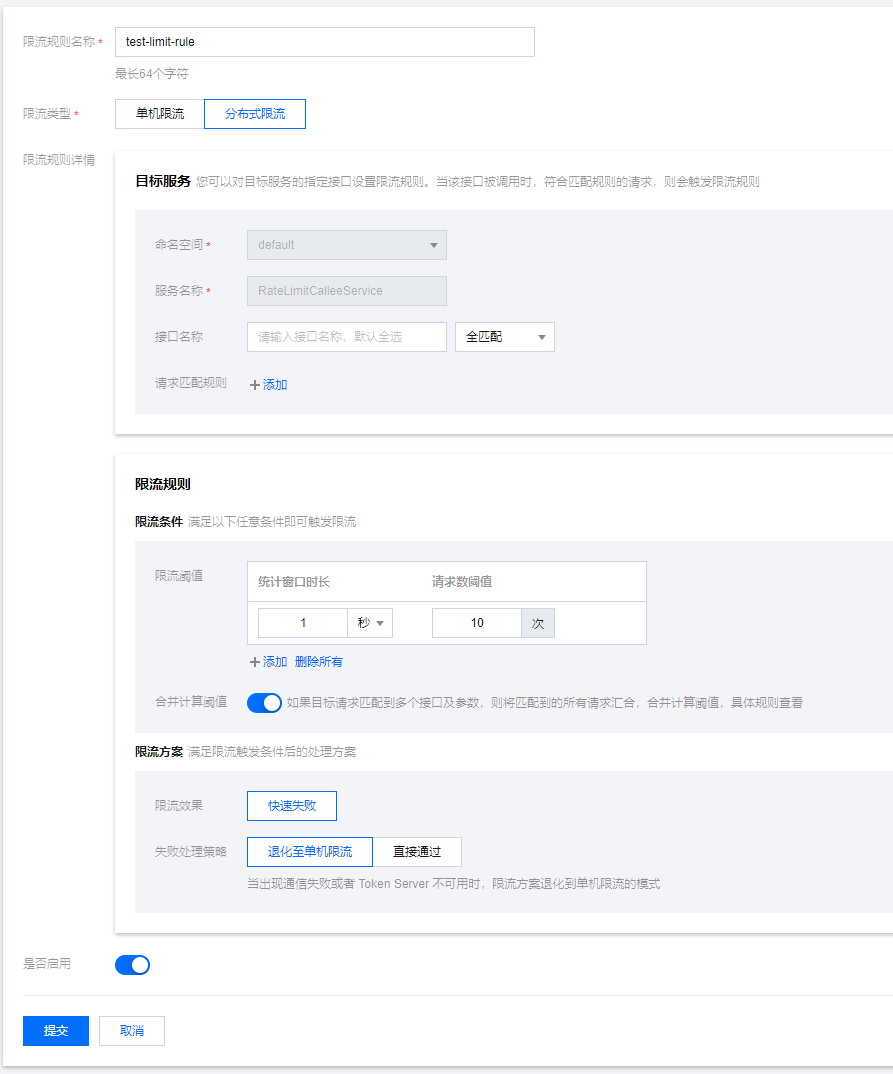
针对服务进行限流
在RateLimitServiceJava服务下新建限流规则,指定QPS为10,限流效果选择直接拒绝。
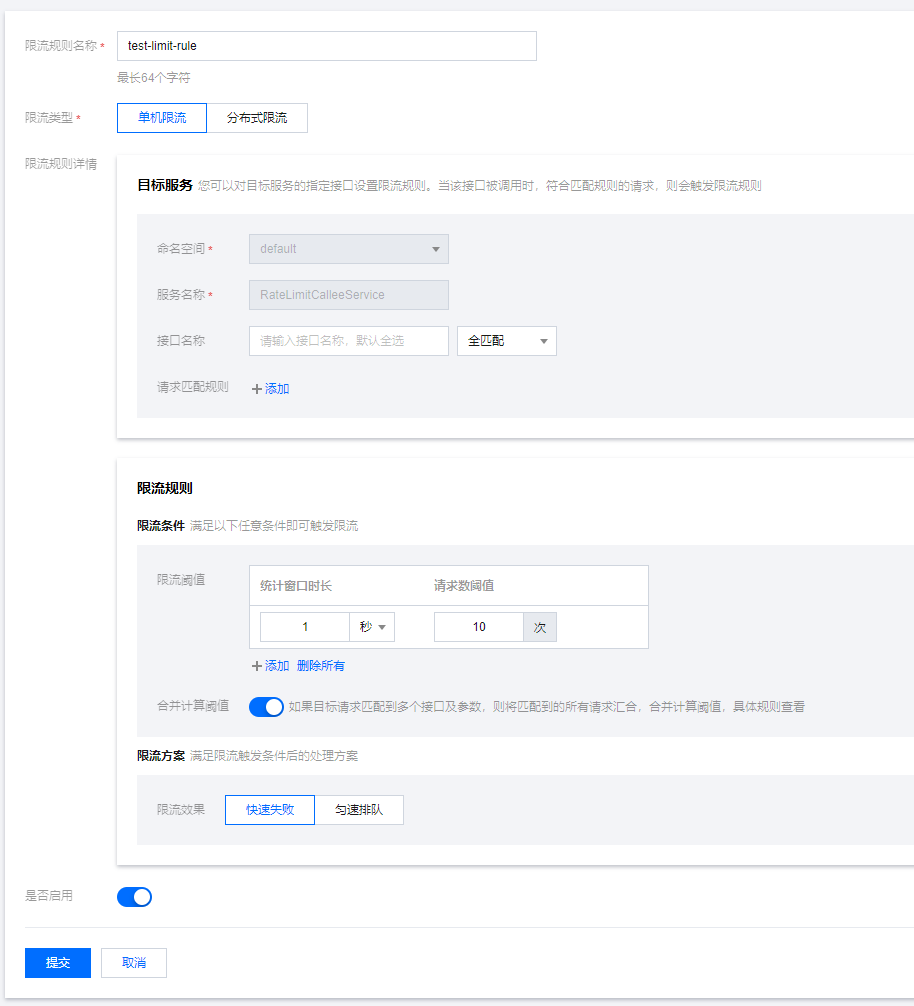
针对接口+标签进行细粒度限流
在 RateLimitServiceJava 服务下新建限流规则,指定QPS为10,方法名为/echo,针对 http 请求中的 header user=foo 进行限流,限流效果选择直接拒绝。
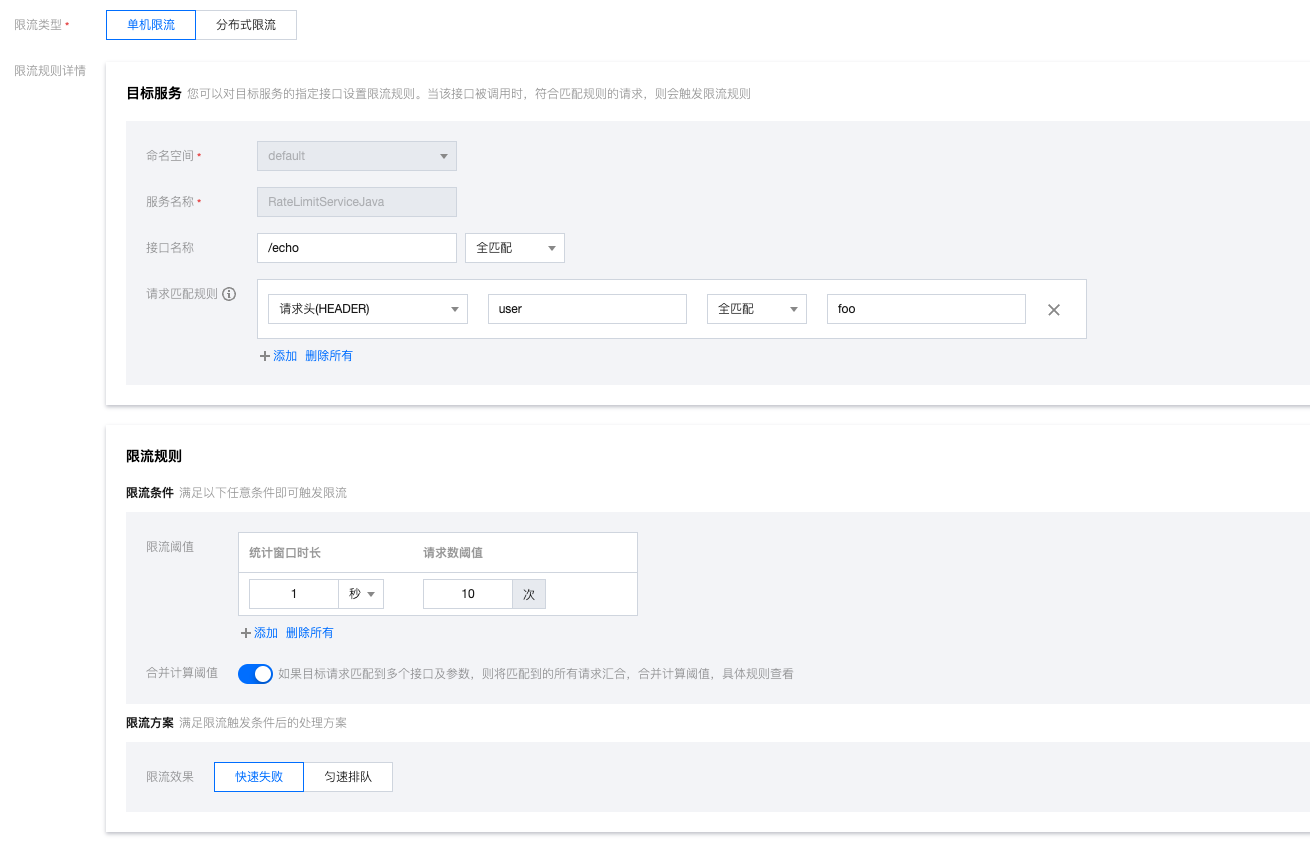
针对接口+标签进行热点参数限流
在 RateLimitServiceJava 服务下新建限流规则,指定QPS为10,方法名为/echo,针对 http 请求中的 header user的每一个参数值进行单独限流,限流效果选择直接拒绝。
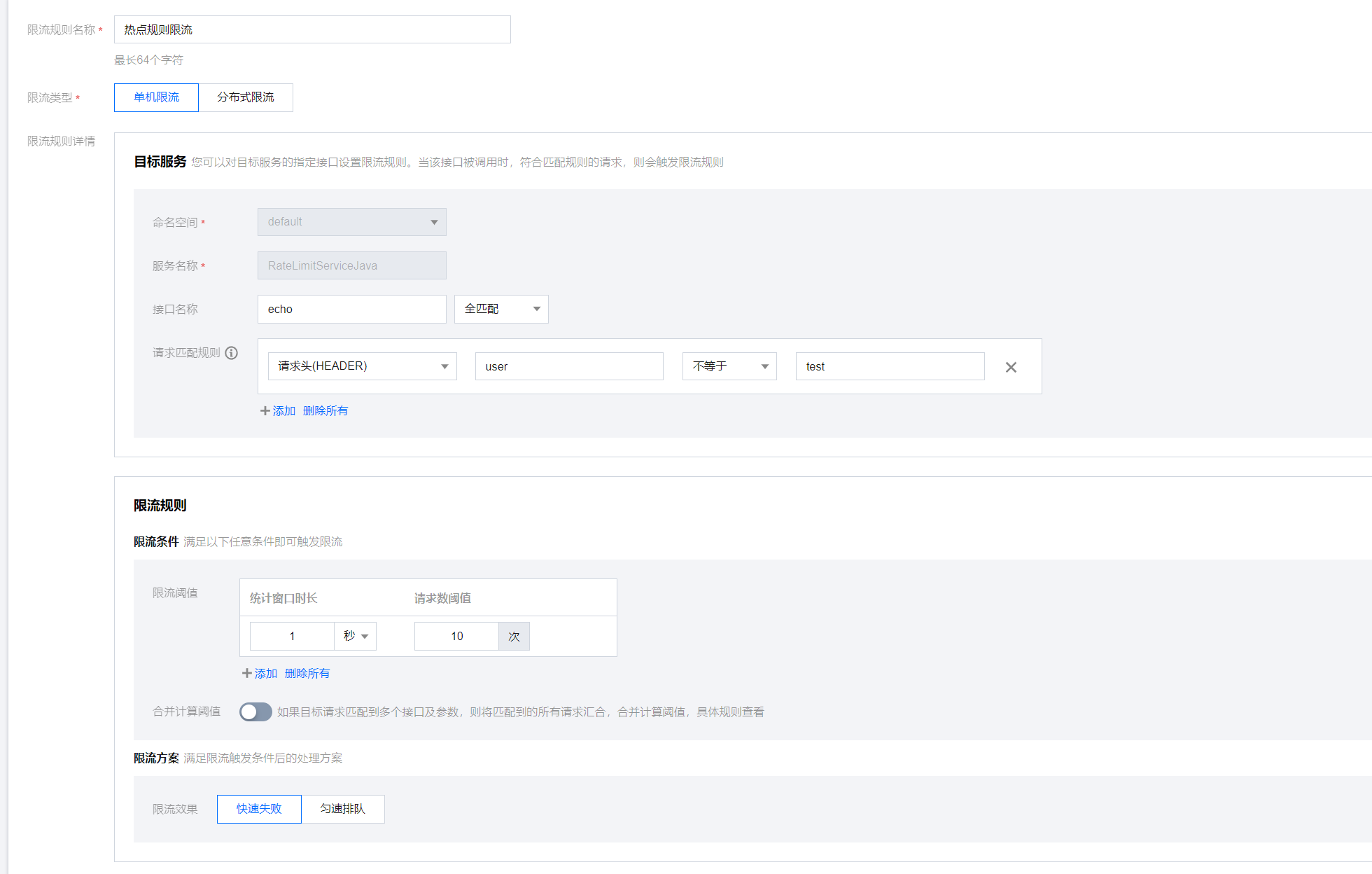
热点参数限流规则配置需要满足2个条件,否则无法生效:
- 存在非全匹配规则。”接口名称“、”请求匹配规则“配置中至少存在一条规则是非全匹配规则,比如”不等于“;如果全是全匹配规则,那该限流只是普通限流。
- 不启用”合并计算阈值“。
热点参数限流是一种针对高并发请求中某些热点参数的限流策略;如上述规则的限流效果图如下:
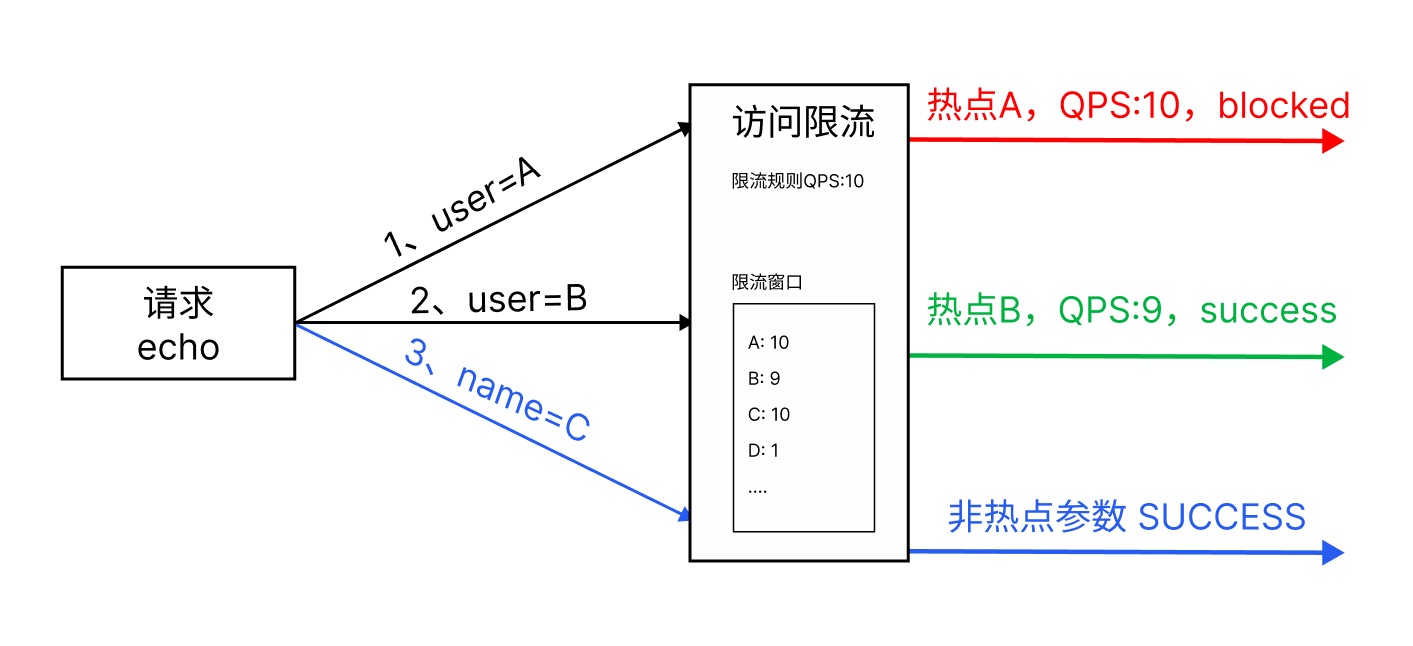
使用匀速排队
在RateLimitServiceJava服务下新建限流规则,指定QPS为10,限流效果选择匀速排队。
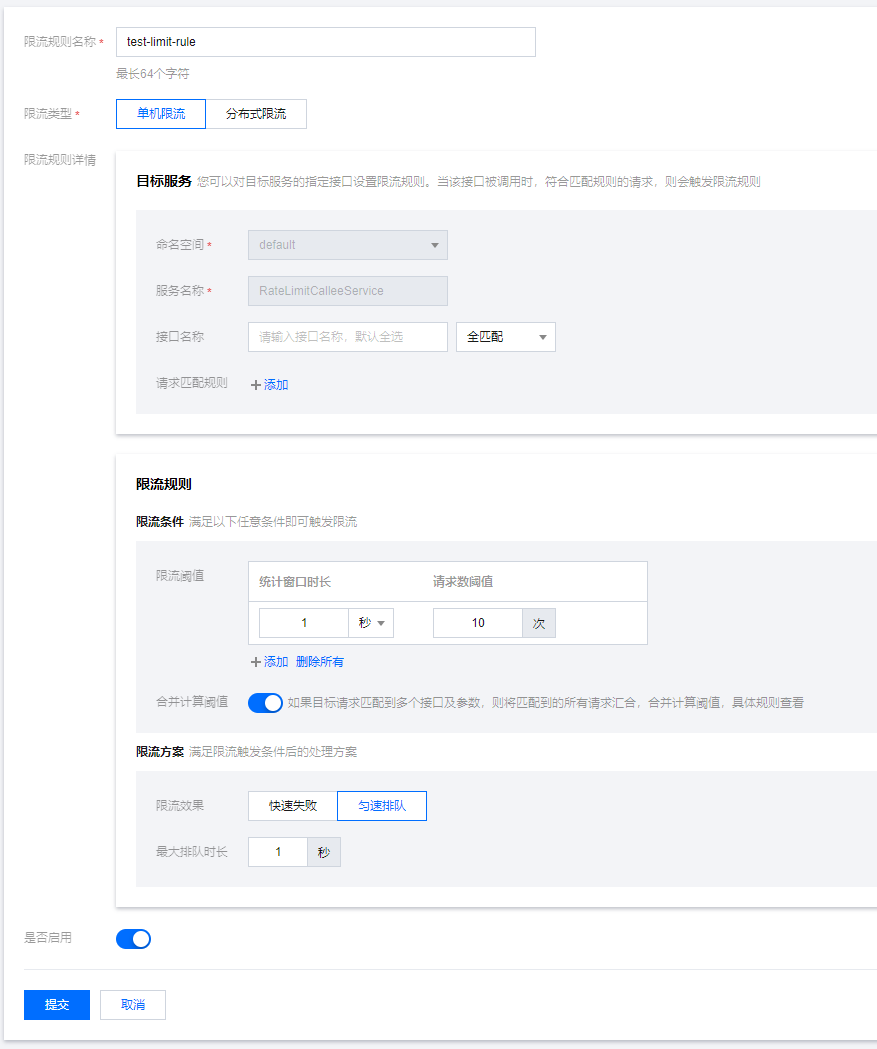
4 - 熔断降级
熔断规则说明
北极星支持在界面配置熔断规则,通过打开北极星控制台,在左侧边栏选择”熔断降级“,可打开熔断降级规则列表,分为3个子TAB,分别配置服务级熔断规则、实例级熔断规则、主动探测规则。
服务级熔断规则
点击新建熔断规则,可以新建服务级熔断规则。服务级熔断规则用于针对特定服务或者服务下的接口进行熔断。
界面各字段含义如下:
基础信息
- 规则名称:规则名,需全局唯一。
- 描述:规则的描述信息,用于补充规则的说明。
匹配条件
匹配条件主要用于决定熔断规则的适用范围,客户端根据匹配条件来过滤本地调用所适用的熔断规则。
- 主调服务:配置作为主调方的服务名和命名空间,可选。不配置则默认对所有的主调生效。
- 被调服务:配置被调的服务名和命名空间,可选。不配置则默认对所有的被调生效。
- 被调接口:配置被调的接口名,表明该熔断规则只对调用某个接口的请求生效,可选。接口名支持多种匹配条件,具体匹配条件可参考:字符串匹配方式
另外,熔断规则中所填的服务名,可为任意服务名,不一定需要存在于北极星注册中心。
熔断配置
- 错误判断条件:可配置多个判断条件,满足任意一个条件的请求会被标识为错误请求。支持返回码和时延2种判断方式。
- 熔断触发条件:可配置多个触发条件,满足任意一个条件即会触发熔断,资源会进入熔断状态。支持连续错误数和错误率2种触发条件。
- 连续错误数:统计调用该服务/接口的请求连续错误数,达到阈值即触发熔断。
- 错误率:统计在周期内调用该服务/接口的请求的错误率,达到阈值即触发熔断。同时为避免少流量下的放大效应,可配置错误率统计的起始请求阈值,请求数超过阈值才进行熔断判断。
- 熔断粒度:指定熔断的资源粒度,支持接口(按单个接口进行统计并熔断,只熔断单个接口),以及服务(按服务维度来统计并熔断,熔断整个服务)。
- 熔断恢复:资源触发熔断后,会熔断请求调度到该资源一段时间。随后系统会对资源进行恢复尝试,当满足一定次数的连续成功请求数后,资源会恢复正常状态。用户可配置资源熔断时长(单位秒),以及连续成功请求数。
主动探测
可选择开启主动探测。开启后,主调方会根据被调服务/接口所关联的探测规则,向被调方发起探测,探测结果会与业务调用合并,作为熔断触发或恢复的依据之一。
熔断后降级
可选择开启降级。开启后,当服务/接口被熔断后,访问该服务/接口的请求,会以自定义响应的方式访问给主调方。
- 返回码:自定义响应的返回码。
- Headers:自定义响应的消息头,可添加多个。
- Body:自定义响应的消息体。
是否开启
选择是否开启该规则。
实例级熔断规则
点击新建熔断规则,可以新建实例级熔断规则。实例级熔断规则用于针对特定分组下多个服务实例或者单个服务实例进行熔断。
界面各字段含义如下:
基础信息
- 规则名称:规则名,需全局唯一。
- 描述:规则的描述信息,用于补充规则的说明。
匹配条件
匹配条件主要用于决定熔断规则的适用范围,客户端根据匹配条件来过滤本地调用所适用的熔断规则。
- 主调服务:配置作为主调方的服务名和命名空间,可选。不配置则默认对所有的主调生效。
- 被调服务:配置被调的服务名和命名空间,可选。不配置则默认对所有的被调生效。
- 被调接口:配置被调的接口名,表明该熔断规则只对调用某个接口的请求生效,可选。接口名支持多种匹配条件,具体匹配条件可参考:字符串匹配方式
另外,熔断规则中所填的服务名,可为任意服务名,不一定需要存在于北极星注册中心。
熔断配置
- 错误判断条件:可配置多个判断条件,满足任意一个条件的请求会被标识为错误请求。支持返回码和时延2种判断方式。
- 熔断触发条件:可配置多个触发条件,满足任意一个条件即会触发熔断,资源会进入熔断状态。支持连续错误数和错误率2种触发条件。
- 连续错误数:统计调用该实例的请求连续错误数,达到阈值即触发熔断。
- 错误率:统计在周期内调用该v的请求的错误率,达到阈值即触发熔断。同时为避免少流量下的放大效应,可配置错误率统计的起始请求阈值,请求数超过阈值才进行熔断判断。
- 熔断粒度:指定熔断的资源粒度,支持实例(按单个实例进行统计并熔断)。
- 熔断恢复:资源触发熔断后,会熔断请求调度到该资源一段时间。随后系统会对资源进行恢复尝试,当满足一定次数的连续成功请求数后,资源会恢复正常状态。用户可配置资源熔断时长(单位秒),以及连续成功请求数。
主动探测
可选择开启主动探测。开启后,主调方会根据被调服务/接口所关联的探测规则,向被调方发起探测,探测结果会与业务调用合并,作为熔断触发或恢复的依据之一。
是否开启
选择是否开启该规则。
主动探测规则
用户可配置主动探测规则,指定被调服务通过什么方式进行探测,探测结果将作为被调资源熔断及恢复的依据。
界面各字段含义如下:
- 规则名称:必选。规则名,需全局唯一。
- 描述:可选。规则的描述信息,用于补充规则的说明。
- 命名空间:必选。被调服务的命名空间。
- 服务名称:必选。被调服务的名称。
- 接口名称:可选。被调接口的名称,支持多种匹配条件,具体匹配条件可参考:字符串匹配方式。
- 周期:可选。探测周期,多久执行一次探测,默认30秒。
- 超时时间:可选,探测最大超时时间,超时未响应则以最大超时时间作为熔断依据。默认60秒。
- 端口:可选,探测端口,默认为服务实例端口。
- 协议:使用什么协议进行探测,会影响接下来的配置,支持HTTP, TCP, UDP 3种协议。
- HTTP协议配置:
- 方法:HTTP方法,默认Get。
- Url:探测Url,默认/。
- Headers:发送探测包所需的消息头,默认空。
- Body:发送探测包所需的消息体,默认空。
- TCP协议配置:TCP默认会采用tcp connect的方式进行探测,用户也可以配置基于报文的探测手段。
- Send:配置所需发送的TCP二进制报文,格式为0x开头的十六进制字符串,如:0x12ab。
- Receive:配置所接收的TCP二进制报文,可配置多个,不配置则不校验应答。
- UDP协议配置:UDP没有连接检测的方式,只能通过基于报文的探测手段。
- Send:配置所需发送的UDP二进制报文,格式为0x开头的十六进制字符串,如:0x12ab。
- Receive:配置所接收的UDP二进制报文,可配置多个。
北极星客户端具体使用哪种协议进行探测,与被探测实例的端口协议有关,主要获取的是实例的protocol属性,对应关系如下:
| 探测协议 | 服务实例的Protocol |
|---|---|
| HTTP | http, HTTP, tcp/http |
| TCP | tcp, gRPC |
| UDP | udp |
客户端接入
附录
字符串匹配方式
熔断规则使用公共的字符串匹配对话框,对话框支持多种匹配模式:
- 全匹配:实际请求字段与文本框所填内容全匹配,区分大小写。
- 正则表达式:文本框所填内容为正则表达式,实际请求字段需匹配所填的正则表达式,遵循Google Re2标准。
- 不等于:实际请求字段不等于文本框所填内容,区分大小写。
- 包含:文本框所填内容为多段的文本,以逗号来进行分割。实际请求字段内容必须全匹配其中某一段文本。
- 不包含:文本框所填内容为多段的文本,以逗号来进行分割。实际请求字段内容必须全不等于其中任何一段文本。