故障容错
熔断降级
故障熔断,指的是当下游因过载或者BUG等原因,出现请求错误后,为了防止故障级联扩散导致整个链路出现异常,从而对请求进行拒绝或者重试的一种机制。
熔断模型
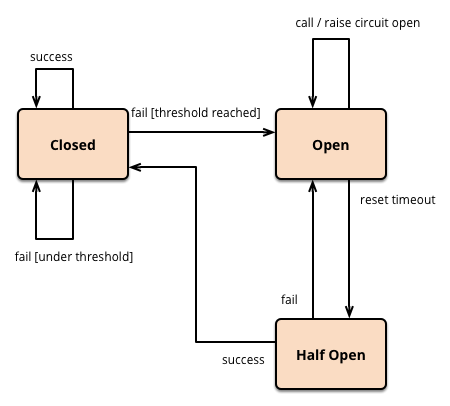
熔断模型的设计遵循业界标准的熔断器模型设计。熔断器有3类状态:
- 关闭:所有请求皆可访问下游资源,无任何限制。
- 打开:限制访问下游资源的请求,不允许任何请求的访问。
- 半开:限制访问下游资源的请求,只允许部分请求达到下游。
熔断场景
熔断一般会发生在以下场景下:
硬件环境出现故障
服务在运营过程中,因为一些不可抗力的因素,可能会出现机器故障、机器重启、机房断电、网络中断等问题。通过熔断机制,对服务实例或者机房分组的快速熔断,可以避免业务请求持续失败。
版本上线引入BUG
版本新特性开发上线后,因为漏测等原因,某些分支触发了BUG,导致部分的业务逻辑出现故障。常见的是部分方法在遇到某些入参的时候,会出现进程报错或者高负载的问题,影响其他方法的请求处理。通过熔断机制,将故障方法进行隔离,可以避免其他业务请求受到影响。
服务出现过载
因为路由不均或者峰值流量的到来,导致被调服务出现了高负载,导致请求的时延增大,成功率降低。通过熔断机制,合理的拒绝一部分请求,可以降低服务负载,恢复正常的运行状态。
熔断级别
服务级熔断
按照服务粒度进行熔断统计,服务一般对应的是注册中心上注册的服务,实际对应到业务可以是应用或者模块。一旦服务被熔断后,访问该服务的请求都会返回失败走降级逻辑
方法级熔断
按照服务下提供的方法进行熔断统计,方法被熔断后会对请求进行拒绝或者走降级逻辑。
分组级熔断
按照服务实例分组进行熔断统计,实例分组被熔断后,请求往往会重路由到其他实例分组。
实例级熔断
按照具体的服务实例进行熔断统计,实例被熔断后,请求往往会重路由到其他实例。
组合粒度
按照组合的粒度进行熔断统计,常见的组合是方法+实例的组合,对应的场景是,一个实例提供了多个方法,其中一个方法在新版本上线时候出现了BUG,需要对该实例下对应的方法进行熔断,其他方法没有改动,可以正常提供服务。
触发熔断条件
连续错误数熔断
请求调用时,统计周期内,出现连续异常数目超过阈值之后,资源进入熔断状态。
错误率熔断
熔断器按照滑窗对请求总数及成功数进行统计,并汇总时间段内的总错误率,一旦超过阈值,资源进入熔断状态。
错误数熔断
熔断器按照滑窗对请求总数及成功数进行统计,并汇总时间段内的总错误数,一旦超过阈值,资源进入熔断状态。
慢调用率熔断
熔断器按照滑窗对请求总数及慢调用数进行统计,并汇总时间段内的总慢请求率,一旦超过阈值,资源进入熔断状态。
熔断策略
快速失败熔断
一旦触发熔断,则接下来的熔断周期内对资源的访问会自动地被拒绝或重路由。
适用于硬件环境出现故障,以及版本上线出现BUG的快速熔断场景。
代表的算法有Hystrix。

每个请求进入后,会判断熔断器状态,存在3种分支:
- 熔断器打开后,请求直接返回,走降级逻辑。
- 熔断器半开后,则只需要一定量的请求访问下游,其他请求返回。
- 熔断器关闭后,所有请求都可以访问下游。
在请求调用后,通过框架采集请求的调用结果,汇聚熔断器。
熔断器会通过滑窗的方式,统计每个请求的成功数及总请求数,根据成功失败率进行状态转换:
- 熔断器从关闭到打开:一旦请求达到阈值,则熔断器打开。
- 熔断器从打开到半开:熔断器打开经过一段时间,或者通过了故障探测,则进入半开状态。
- 熔断器从半开到打开:熔断器半开后,走递增放量的方式,放量期间出现了失败,则熔断器重新打开。
- 熔断器从半开到关闭:熔断器半开后,走递增放量的方式,放量期间没有失败,最终放量100%后,熔断器关闭。